K8s Troubleshooting

Depois do post Técnicas-de-Troubleshooting algumas pessoas me perguntaram como poderiam aplicar aquelas técnicas no dia a dia de quem dá suporte a uma infraestrutura baseada em Kubernetes?
Este post é uma das respostas possíveis!! Montei uma trilha que eu seguiria etapa por etapa em caso de problemas. Cada uma das etapas podem ter diversas bifurcações dependendo da versão do Kubernetes, depende do local onde ele está instalado: seja on-premise, seja no fornecedor de nuvem X, Y ou Z, se é um cluster simples ou tem outras ferramentas de suporte instalada, todas essas variáveis adicionam complexidade ao ambiente e tornam o processo de troubleshooting um pouco mais complexo.
O exemplo a seguir é um modelo simplificado que tenta contemplar alguns problemas com os quais eu tive oportunidade de lidar. Esse também é um cenário possível quando queremos colocar uma aplicação no ar e não existe a infraestrutura para suportar a aplicação, eu normalmente sigo a técnica Bottom-up, nesta técnica o ponto de partida é olhar como o código é compilado e vamos construindo e testando camada por camada até a parte mais externa que é a interface de comunicação com o cliente.
Veja como ficou e o que é importante observar em cada uma das camada:
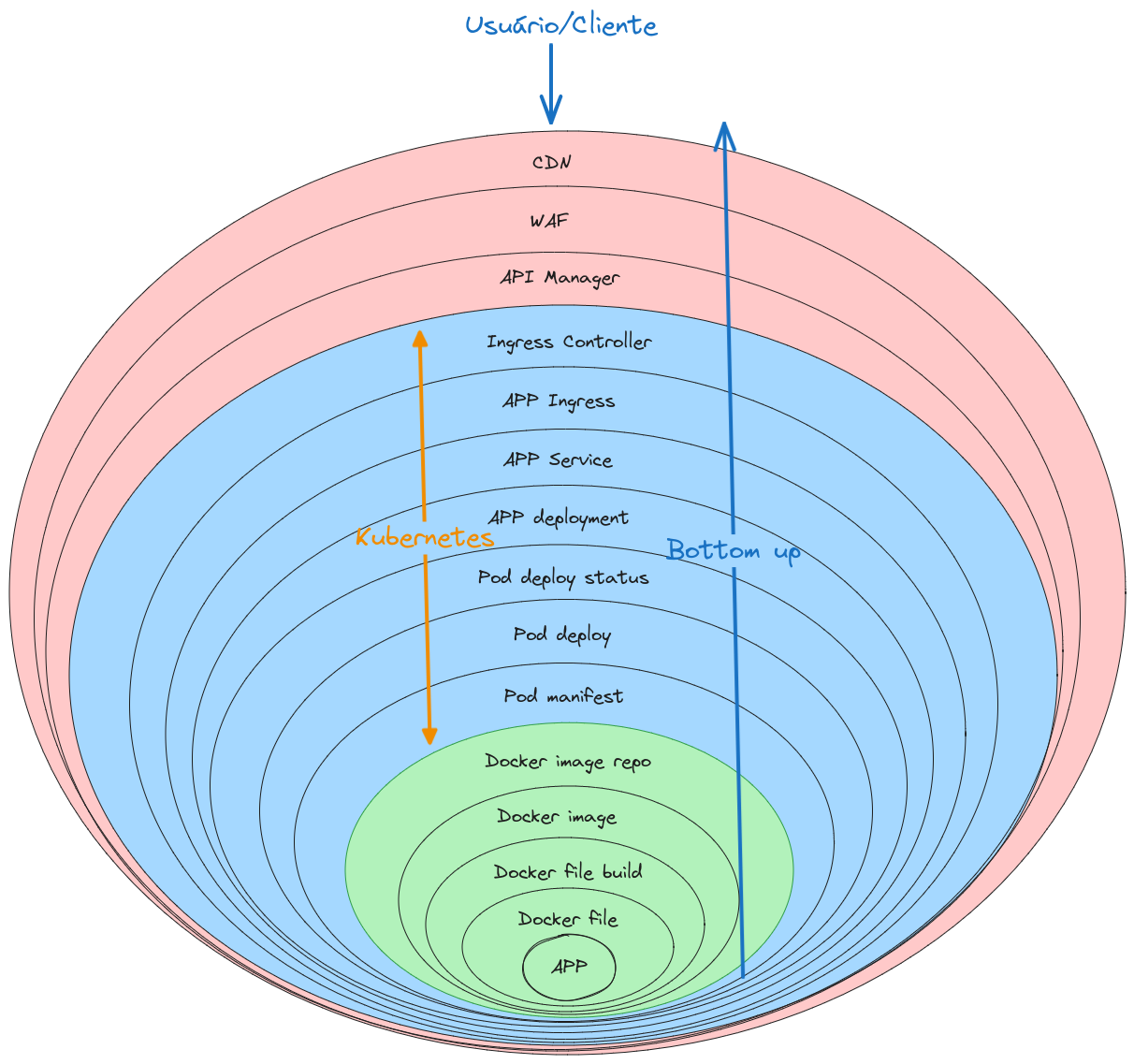
Image: Infra as Code
Iniciando as validações
-
APP:
- Aqui é ponto de partida da jornada de troubleshooting. e a razão de se construir a infra, o código tem como objetivo realizar alguma tarefa.
-
Docker:
- Esse é ponto onde se coloca o código dentro de um local para ser executado https://docs.docker.com/develop/develop-images/dockerfile_best-practices/
-
Docker file build:
-
Esse é o ponto que você verifica se a APP foi copiada para o local certo
-
É bom conhecer a função do comandos FROM, COPY, ENTRYPOINT, WORKDIR
-
Para garantir que funciona recomendo executar a imagem localmente e testar se a aplicação funciona
-
-
Docker image
-
Verificar o tamanho da imagem isso impacta na hora do deploy quanto menor melhor
-
Verificar os privilégios do usuário que vai executar a imagem. NUNCA rodar como ROOT
-
Verificar as TAGs de versionamento, última data de atualização
-
Lembre-se que uma imagem é construída em camadas
-
Inclua health e liveness checks
-
Se possível assine a imagem com Docker Content Trust (DCT)
-
-
Docker image repo
-
Verificar se a imagem está no repo
-
Verificar as TAGs de versionamento batem com a última data de atualização
-
Agora estamos entrando no universo Kubernetes
-
Pod Manifest
-
Verifique a imagem, sempre use uma versão específica nunca use latest
-
Verifique os labels e annotations
-
Verifique os readiness e liveness probes
-
Verifique as portas que o Pod vai abrir
-
Verifique o namespace de trabalho do pod
-
-
Pod deploy
De longe este é o ponto onde os erros mais acontecem, por isso é fundamental conhecer os cinco tipos de status de um POD segundo a documentação oficial.
- Verifique a(s) porta(s) que o Pod vai abrir
- Verifique o namespace de trabalho do pod
- Verifique o status do pod com os comandos abaixo:
1 $ 𝘬𝘶𝘣𝘦𝘤𝘵𝘭 𝘭𝘰𝘨𝘴 <𝘱𝘰𝘥_𝘯𝘢𝘮𝘦>
2 $ 𝘬𝘶𝘣𝘦𝘤𝘵𝘭 𝘨𝘦𝘵 𝘱𝘰𝘥 <𝘱𝘰𝘥_𝘯𝘢𝘮𝘦>
3 $ 𝘬𝘶𝘣𝘦𝘤𝘵𝘭 𝘥𝘦𝘴𝘤𝘳𝘪𝘣𝘦 𝘱𝘰𝘥 <𝘱𝘰𝘥_𝘯𝘢𝘮𝘦>
4 $ 𝘬𝘶𝘣𝘦𝘤𝘵𝘭 𝘨𝘦𝘵 𝘦𝘷𝘦𝘯𝘵𝘴
Possíveis status de um Pod
A documentação oficial do Kubernetes diz que no ciclo de vida de um Container ele pode ter os seguintes estados:
Pending: O pod foi aceito pelo cluster Kubernetes, mas um ou mais contêineres não foram configurados e preparados para execução. Isso inclui o tempo que um pod gasta esperando para ser agendado, bem como o tempo gasto no download de imagens de contêiner pela rede.
Running: O pod foi vinculado a um nó e todos os contêineres foram criados. Pelo menos um contêiner ainda está em execução ou em processo de inicialização ou reinicialização.
Succeeded: Todos os contêineres no pod foram encerrados com êxito e não serão reiniciados.
Failed: Todos os contêineres no pod foram encerrados e pelo menos um contêiner foi encerrado com falha. Ou seja, o contêiner saiu com status diferente de zero ou foi encerrado pelo sistema.
Unknown: Por algum motivo, não foi possível obter o estado do pod. Essa fase normalmente ocorre devido a um erro na comunicação com o nó onde o pod deveria estar em execução.
-
APP deployment:
Essa é a parte com muitas etapas a serem validadas:
-
Verifique a TAG de build bate com a versão da APP “deployada”
-
Verifique o namespace de trabalho
-
Verifique os labels e annotations
-
-
APP service:
-
Verifique a porta e protocolo de comunicação com o POD
-
Verifique a porta e protocolo de comunicação com os componentes externos
-
Verifique o tipo de serviço escolhido: ClusterIP, NodePort, LoadBalancer ou ExternalName
-
Verifique as TAGs os labels e annotations do componente
-
Verifique o namespace de trabalho
-
-
APP ingress
-
Verifique o namespace de trabalho pod
-
Verifique as políticas de rede do K8s
-
Verifique o service da sua aplicação está funcionando
-
-
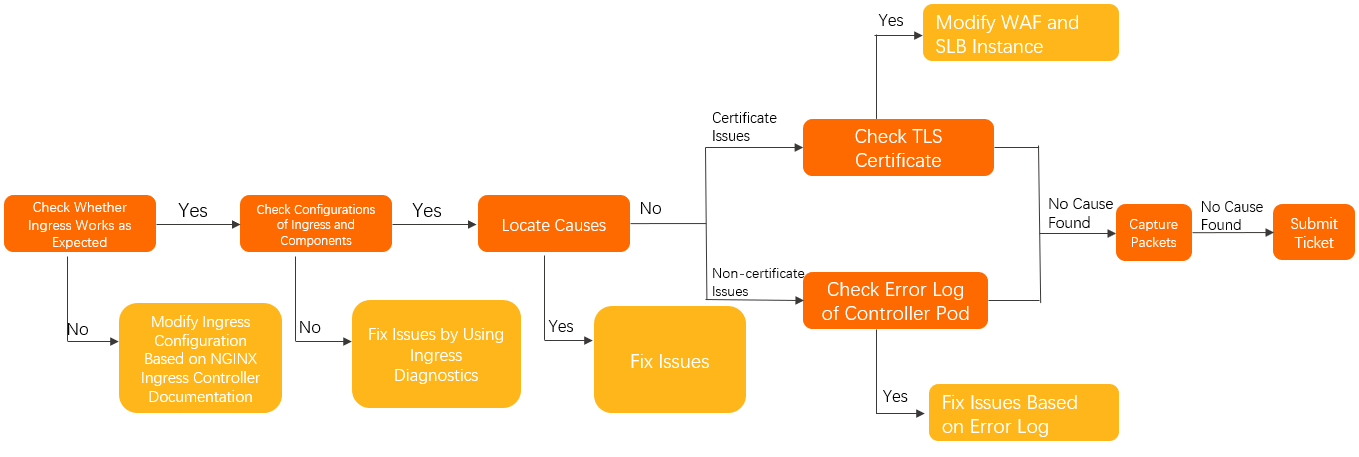
APP ingress controller
-
Verifique o namespace de trabalho
-
Siga o fluxo abaixo:
-
Agora saímos do universo Kubernetes
-
API manager
-
Verifique os “paths” criados
-
Verifique os backends dos “paths” criados
-
Teste os mecanismos de throttling e de limitações de tentativas
-
Use https sempre » OBRIGATÓRIO «
-
Use autenticação para comunicação externa
-
Use token para comunicação interna gente por favor
-
-
WAF - Web Application Firewall
-
Verifique as regras criadas
-
Verifique se as regras criadas batem “se dão match” com o configurado
-
Testes variações das regras. RegExp genéricas demais sempre deixam passar coisas 👀
-
-
CDN
-
Valide se os objetos estão sendo guardados “cacheados”
-
Apague coisas do cache e valide novamente
-
Verifique a “idade” dos objetos e suas data da expiração
-
-
K8s Troubleshooting fluxo visual
Você pode também seguir esse fluxo visual
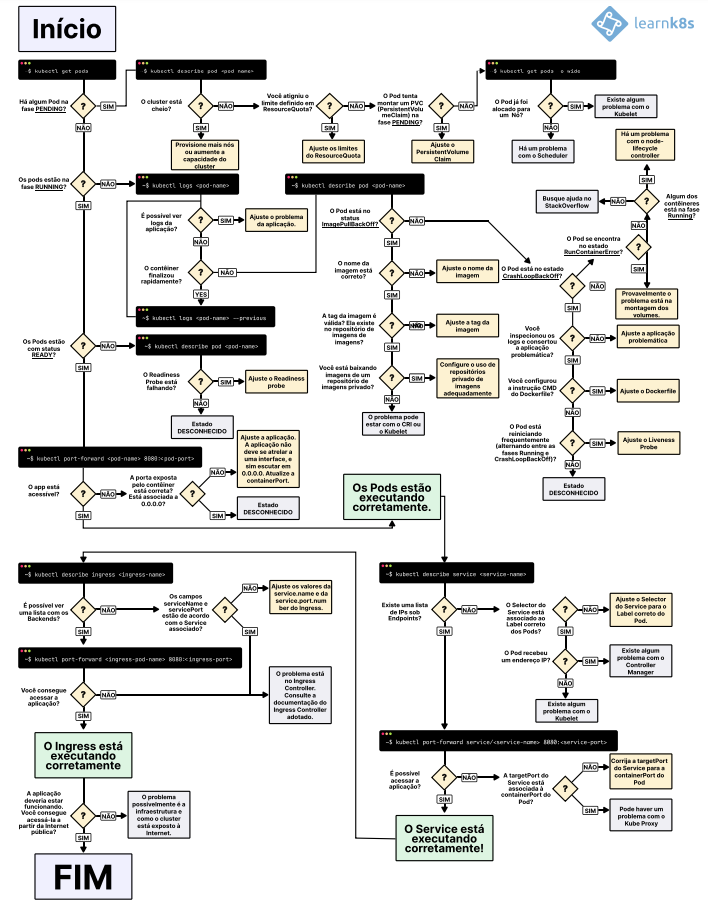
Conclusão
Se você fizer todas essas validações até a última camada você estará pronto para dizer para o gerente de projetos “está funcionando no ambiente de DEV 🙂, falta validar em QA e no ambiente de Produção 🙂🙂“.
Pode parecer assustador num primeiro momento mas não é, mas com toda certeza dá trabalho e consome muito tempo fazer tudo isso todas as vezes para todos os microsserviços que se cria. E como reduzir o tempo de validação de cada etapa? Automação, a beleza da automação esse é o jump of the 😺 (sacou que meu inglês é literal). Todas, eu disse todas essas etapas podem ser automatizadas e você pode utilizar ferramentas de configuração ou templates de configuração ajustados por ambiente e replicar para 100, 200, 1000 microsserviços que seu trabalho não vai aumentar. Pense nisso e curta a beleza da automação com infra as code (IaC).
Referências
- https://docs.docker.com/develop/develop-images/dockerfile_best-practices/
- https://docs.docker.com/get-started/09_image_best/
- https://docs.docker.com/engine/reference/builder/#healthcheck
- https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/
- https://kubernetes.io/docs/concepts/services-networking/service/#publishing-services-service-types
- https://kubernetes.io/docs/concepts/services-networking/network-policies/
- https://www.alibabacloud.com/help/en/ack/ack-managed-and-ack-dedicated/user-guide/nginx-ingress-controller-troubleshooting
- https://learnk8s.io/a/a-visual-guide-on-troubleshooting-kubernetes-deployments/troubleshooting-kubernetes.pt_br.v3.pdf
Abraços!
Vida longa e próspera a todos!!
Entre em contato:
NewsLetter - https://engineeringmanager.com.br/Linkdin - linkedin.com/in/leonardoml/
Twitter: @infraascode_br
Te convido a ver os outros posts do blog Infra-as-Code garanto que tem coisas legais lá!!
|
|
