Monitoração e Observability

Jovens!! Por esses dias eu estava em um papo técnico com uns amigos e ouvi várias vezes a palavra observability em um período curto de tempo, isso chamou a minha atenção, porque observability ganhou esse status?! Fiquei pensando, quando foi que a Monitoração virou Observabilidade?? Humm!!?? Fui atrás de tentar responder a essa minha pergunta interna….. e descobri que ….
Monitoração
Monitorar significa observar e verificar um progresso ou qualidade de algo por um certo período de tempo. Do ponto de vista de operações, a monitoração foi mudando conforme a infraestrutura e ferramentas disponíveis ao longo do tempo.
Meus primeiros contatos com as ferramentas de monitoração foram com o MRTG, Nagios e Cacti essas ferramentas fazem parte do modelo de monitoração chamado, passivo e reativos, elas informam um problema depois que ele ocorreu. Combinando essas três ferramentas tinha-se uma maneira de achar e resolver os problemas. Lembrando, essa era uma época beeeemmm pré-DEVOPS, logo, ter os links de Internet funcionando, serviços e algumas poucas máquinas funcionando era a minha função, então, essa monitoração era suficiente para detectar os falhas, fazer análises de resolução de problemas, gerar relatórios e projeções para upgrade de links, equipamentos de redes e servidores.
Observability
O tempo passou, a infraestrutura mudou, agora temos, virtualização on premises com gerenciamento de VMs, containers, cluster de gerenciamento de containers, máquinas físicas na cloud 😳, máquinas virtuais na cloud, cluster de containers na cloud, arquitetura Serverless 😳 😳 na cloud, isso falando só de componentes de infraestrutura.
Do ponto de vista de componentes de software as arquiteturas de hoje possuem Micros Serviços, Micros Serviços chamando Micros Serviços, API gateway; Proxy, Load Balancers, integração de sistemas, HTTP request para componentes externos, teste A/B, teste Blue/Green. Em algumas empresas métricas de desempenho de aplicações, tempos de deploy, Frequência de deploy, tempo de detecção de falhas e tempo de recuperação de falhas são exemplos de algumas métricas perseguidas.
Dentro de um contexto de trabalho DEVOPS, SRE, Production Engineer é preciso olhar para as diversas infraestruturas e para as aplicações como sistemas complexos interagindo com outros sistemas complexos. Diante deste cenário, uma métrica de CPU ou de utilização de memória uma máquina ou um tempo X qualquer de uma atividade isoladamente não são capazes de representar se uma aplicação vai bem ou vai mal. É a partir desse ponto que passamos a chamar a monitoração de Observabilidade ou Observability. O conceito de Observability apresentado por Rudolf_E._Kálmán aplicado em sistemas dinâmicos lineares, diz o seguinte; pode-se dizer que é uma medida de quão bem os estados internos de um sistema podem ser inferidos a partir do conhecimento de suas saídas externas.
Padrões de Monitoração e de Observability
Por onde começar a implementação da Monitoração com Observability? A primeira coisa a ser dita, é que, Observability é um destino a ser alcançado, e o valor está na jornada a ser percorrida, portanto, você nunca vai chegar lá e dizer Voila!!. Não, não é assim jovem!! É um caminho de melhoria contínua com diversas etapas, uma complementando a outra e cada uma avançando alguns centímetros por vez.
Seja qual for o caminho da sua jornada você precisa conhecer algumas peças importantes desse grande quebra-cabeça. A metodologia 12 Factors precisa ser um mantra que ecoe na sua mente executado em loop infinito. Para a Observability recomendo uma especial atenção ao item XI. Logs: Treat logs as event streams. Os sistemas monitorados devem gerar eventos com métricas, logs, traces e mapas de dependências, todas essas informações devem ser enviadas a um concentrador de eventos e para a criação dos correlacionamentos, dashboards e gráficos em tempo real. Cada componente da sua estrutura deve ser configurado de forma automática para mandar as métricas a partir do minuto zero de funcionamento.
Geração de métricas
O Diagrama 01, é uma representação genérica de uma infraestrutura com múltiplos Micro Serviços, ele foi dividido em quatro partes, para que seja possível explorar diferentes pontos de vistas e detalhar algumas possíveis métricas, ferramentas e técnicas para cada uma das partes dessa arquitetura.
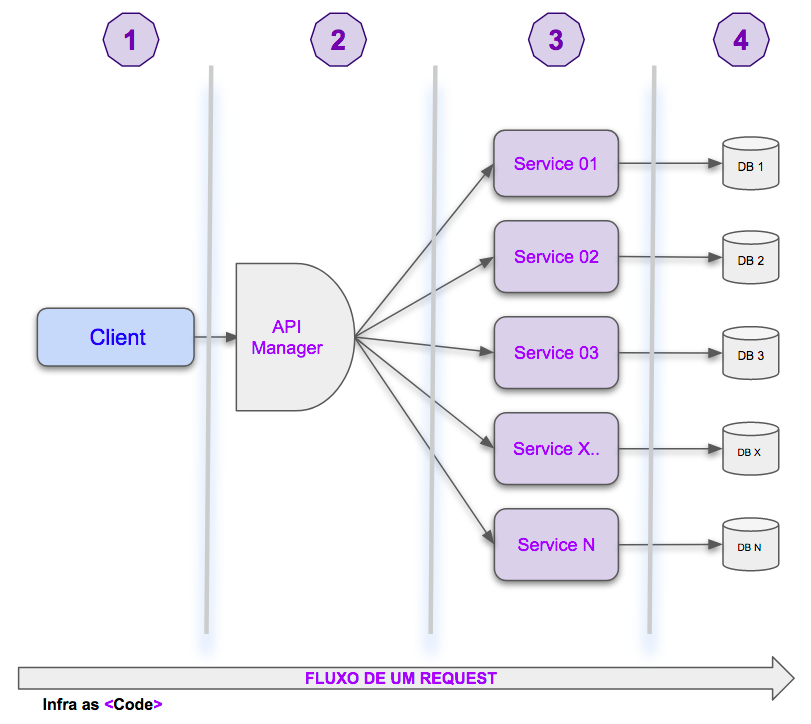
Diagrama 01: Infraestrutura com múltiplos Micro Serviços
- PARTE 1 - CLIENTE
- Monitoração das URLs expostas para o cliente
- Robotic Process Automation (RPA) para validar fluxos
- Ferramentas que capturem response time e taxas de erros
- Web browser injection
- PARTE 2 - API MANAGER
- Ferramenta de Application Performance Management (APM)
- User agent e IP
- Geolocalização da origem do cliente
- Mapeamento de dependências
- Taxas de erro das solicitações para front-end e respostas de front-end
- Taxas de erro das solicitações de back-end e respostas de back-end
- Erros por políticas e restrições da API
- Status de resposta HTTP com códigos 4xx ou 5xx
- PARTE 3 - MÁQUINAS FÍSICAS, VIRTUAIS, POD E/OU SERVELESS
- Ferramenta de Application Performance Management (APM)
- CPU, Memória, disco, rede
- Processos
- IOPS
- PARTE 4 - DATA BASE
- Ferramenta de Application Performance Management (APM)
- Slow queries, top 50
- Taxas de atualização de tabelas
- Distribuição dados
Estratégias de Observability
Conhecendo as métricas é possível aplicar as estratégias Observability: USE Method, RED Method e The Four Golden Signals elas vão ajudar a olhar para o código ou infraestrutura em funcionamento de uma forma holística. Os efeitos de uso dessas estratégias refletem diretamente nas métricas e indicadores de Service Level Agreements (SLA), Service Level Indicator (SLI) e Service Level Objectives (SLO).
USE Method
USE é um acrônimo para Utilização, Saturação e Erros. Criado por Brendan Gregg, é recomendado para extrair alguma informação quando não se conhece nada de um sistema.
- Utilização: o tempo médio que o recurso esteve ocupado atendendo ao trabalho
- Saturação: o grau em que o recurso tem trabalho extra que não pode atender, geralmente enfileirado
- Erros: a contagem de eventos de erro
RED Method
Focado mais em aplicações e micro serviços, o método RED define as três principais métricas que se deve medir para cada componente de sua arquitetura, são elas:
- Rate:Taxa do número de request por segundo
- Erros: Taxa do número de request que falham por segundo
- Duration: Taxa de tempo de duração de cada request
The Four Golden Signals
Essa é a metodologia sugerida pelo Google, segundo eles se você tiver que escolher o que monitorar, as métricas deveriam ser as seguintes:
- Latency: Tempo para servir um request
- Traffic: Total de quanto o seu sistema está sendo solicitado
- Errors: Quantidade de requisições que estão falhando
- Saturação: Quão cheio o seu serviço está
Conclusão
Depois de pesquisar um pouco sobre o assunto, tô mais tranquilo, consegui encontrar uma resposta para a minha pergunta, porque Observability é uma palavra tão repetida nas conversas técnicas?? Monitorar as interfaces de um roteador e as portas de um switch ainda faz sentido hoje? Eu diria que dentro de certos contextos faz sim, mas hoje em dia já tem ferramentas bem melhores, integradas com aplicativos de mensagem é possível receber avisos no celular.
Se você você estiver lidando com aplicações que tenham múltiplos componentes, muitos serviços e muitos pontos de integração e tudo isso numa arquitetura com auto scaling de VM ou de PODs é mais recomendado aplicar os métodos: USE, RED ou The Four Golden Signals e achar um conjunto de ferramentas de monitoração para compor seu repertório de Observability.
Observability é uma palavra que tá na moda… mas comece a pesquisar sobre AIOPS essa semana ouvi umas duas ou três vezes …mas isso é assunto para um outro momento.
Abraços!
Vida longa e próspera a todos!!
DICA RÁPIDA DE LIVRO
Estou lendo atualmente o livro Desafios da gestão (10 leituras essenciais - HBR): Uma introdução às mais influentes ideias da Harvard Business Review
Referências
- Dica de livro Desafios da gestão (10 leituras essenciais - HBR): Uma introdução às mais influentes ideias da Harvard Business Review
- MRTG, https://oss.oetiker.ch/mrtg/
- Nagios, https://www.nagios.org/
- Cacti, https://www.cacti.net/
- https://www.youtube.com/watch?v=TJLpYXbnfQ4
- USE Method, por Brendan Gregg - https://www.brendangregg.com/usemethod.html
- The RED Method, https://grafana.com/blog/2018/08/02the-red-method-how-to-instrument-your-services/
- 4 Golden Signals, https://sre.google/sre-book/monitoring-distributed-systems/
- https://www.weave.works/docs/tutorials/core/monitoring-microservices/
- https://en.wikipedia.org/wiki/Observability
- https://www.ibm.com/cloud/learn/observability
- https://thenewstack.io/monitoring-vs-observability-whats-the-difference/
- https://newrelic.com/blog/best-practices/observability-instrumentation
- Rudolf_E._Kálmán, https://en.wikipedia.org/wiki/Rudolf_E._K%C3%A1lm%C3%A1n
- Observability, https://en.wikipedia.org/wiki/Observability
- AIPOS, https://cio.com.br/tendencias/o-que-e-aiops-e-como-sua-empresa-pode-se-beneficiar-com-a-tecnologia/
Entre em contato:
NewsLetter - https://engineeringmanager.com.br/Linkdin - linkedin.com/in/leonardoml/
Twitter: @infraascode_br
Te convido a ver os outros posts do blog Infra-as-Code garanto que tem coisas legais lá!!
|
|
