Root Cause Analysis - RCA

Um dia desses estava lendo o livro Equipes Brilhantes de Daniel Coyle, ele fala de uma eqipe de atendimento de um restaurante de NY, o responsável técnico fez um discurso motivacional de início do dia com as seguintes palavras, “A única coisa que sabemos do dia de hoje é que não vai ser perfeito. Quero dizer, poderia ser perfeito, mas as chances são muito, muito, muito grandes de que isso não aconteça”. Eu achei a frase excelente!! Eu te explico…
Essa frase expressa bem o dia a dia de um time DevOps, SRE. O nosso trabalho é resolver problemas, problemas grandes, médios, pequenos, mas principalmente problemas novos, a gente não gosta de problemas velhos, sabe por quê? Porque a gente trabalha com métodos estruturados para achar a causa raiz dos problemas. Esses métodos nos ajuda a resolver o problema de uma vez por todas, “na maior parte das vezes 🙂”.
Jovem, vem comigo para entender o que é, e como se faz Root Cause Analysis (RCA) ou numa tradução livre, Análise de Causa Raiz…..Começo a explicação dizendo primeio o que não é uma RCA e depois eu te explico o que é e dou alguns exemplos de como eu a uso…. então bora lá!!
O que não é?
Uma análise de causa raiz não é simplesmente apontar que o primeiro culpado foi culpa do time A, do time B ou C. Esse tipo de atitude inibe qualquer tentativa de colaboração entre times.
Tirar conclusões precipitadas sem dados suficientes leva a correções superficiais, que podem até resolver temporariamente o problema, mas não evitam que ele ocorra novamente. Da mesma forma, tratar apenas os sintomas: como reiniciar um serviço sem entender por que ele falhou cria uma falsa sensação de resolução, deixando a causa real intocada e pronta para se manifestar no futuro. Uma RCA eficaz exige investigação estruturada, dados concretos e uma abordagem sistemática para identificar o verdadeiro ponto de falha.
Problemas complexos raramente surgem de um único erro humano, mas sim de processos deficientes, lacunas na automação ou falhas de projeto que permitem que esses erros aconteçam. Além disso, uma RCA sem um aprendizado contínuo é um esforço desperdiçado. Se as descobertas não resultam em melhorias no sistema, como ajustes nos processos, automação ou monitoramento mais eficaz, a análise perde seu propósito. RCA não é apenas um exercício para apagar incêndios, mas uma oportunidade para tornar a infraestrutura mais resiliente a longo prazo.
O que é?
Um RCA é um processo estruturado para identificar a verdadeira origem de um problema e garantir que ele não volte a ocorrer. O primeiro passo para uma RCA eficaz é esclarecer o problema, definindo com precisão o que está acontecendo, quais sistemas ou processos estão afetados e qual é o impacto real. Incidentes podem parecer similares, mas suas causas podem ser completamente diferentes, um diagnóstico bem formulado evita retrabalho e direciona a equipe para a investigação correta.
Com o problema bem definido, é essencial envolver as pessoas certas na análise. Os membros da equipe que lidam diretamente com os sistemas afetados possuem informações valiosas que ajudam a entender o contexto e os detalhes operacionais. A colaboração entre desenvolvedores, operadores de infraestrutura e equipes de segurança pode revelar padrões que passariam despercebidos em uma análise isolada. Além disso, é fundamental que o ambiente permita contribuições sem medo de represálias ou retaliações garantindo que o foco esteja na melhoria do sistema e não na busca por culpados.
Uma vez identificada a causa raiz, é hora de agir com soluções direcionadas. Em vez de aplicar correções superficiais, a RCA deve focar em mudanças estruturais que eliminem o problema de forma definitiva, seja por ajustes na configuração, automação de processos, reforço de monitoramento ou reformulação de políticas. Além disso, documentar todo o processo garante aprendizado organizacional e facilita consultas futuras. Implementar as soluções de forma controlada, testando uma mudança por vez, evita novos riscos e transforma a RCA em uma ferramenta contínua para fortalecer a resiliência da infraestrutura.
Como fazer?
Léo, você falou aee que seguia uns métodos, como se faz isso? Quais são esses métodos? Boas perguntas, meu jovem, posso sugerir três métodos que eu uso bastante para resolução de problemas e um quarto que é um pocou mais do que a combinação dos primeiros. Bora ver quais são:
Resolução por hipóteses
O método de resolução por hipóteses consiste em formular possíveis causas para um problema e testá-las sistematicamente até encontrar a verdadeira origem da falha. Ele segue um ciclo de
- Observação
- Formulação de hipóteses
- Experimentação
- Validação
No contexto de RCA, isso significa levantar suposições baseadas em dados, testar cada uma de forma controlada e eliminar as incorretas até chegar à causa raiz. Esse método evita soluções precipitadas e garante que o problema seja resolvido de forma definitiva.
Espinha de Peixe
O método Espinha de Peixe, também chamado de Diagrama de Ishikawa, é uma técnica visual usada para identificar e organizar as possíveis causas de um problema. Ele se parece com uma espinha de peixe, onde o “corpo” representa o problema central e os “espinhos” são categorias de possíveis causas, como Pessoas, Processos, Tecnologia, Ambiente, Materiais e Métodos. A ideia é levantar hipóteses dentro dessas categorias e analisar quais fatores podem estar contribuindo para o problema. Essa abordagem ajuda a equipe a visualizar a complexidade da situação, evitar vieses e chegar à causa raiz de forma estruturada. Muito usada em DevOps e operações de TI, ela facilita discussões colaborativas e direciona ações corretivas mais eficazes.
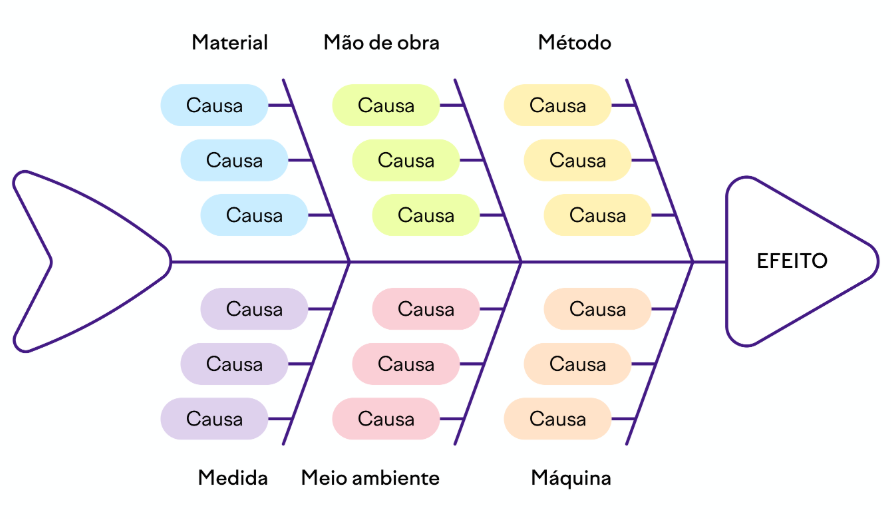
5 Porquês ou 5Ws
O método dos 5 Porquês é uma técnica simples e eficaz para encontrar a causa raiz de um problema, fazendo perguntas sucessivas sobre por que algo aconteceu. A ideia é que, ao questionar repetidamente a causa de um problema, se chega à sua verdadeira origem, em vez de tratar apenas os sintomas. Por exemplo:
- Por que o serviço caiu? Porque o banco de dados ficou indisponível.
- Por que o banco ficou indisponível? Porque a instância principal parou de responder.
- Por que a instância principal parou de responder? Porque o disco atingiu 100% de uso.
- Por que o disco atingiu 100%? Porque os logs não foram rotacionados.
- Por que os logs não foram rotacionados? Porque não havia uma política de rotação configurada.
Entendeu a lógica? Com isso, a solução não é apenas liberar espaço no disco, mas implementar uma política de rotação de logs, evitando que o problema volte a ocorrer. O método é direto, fácil de aplicar e muito útil em RCA para encontrar falhas estruturais.
Postmortem
O Postmortem é um processo estruturado para analisar incidentes, muito utilizado por times DevOps e SRE com o objetivo de aprender com as falhas e evitar que se repitam. Não deve ser uma caça às bruxas, mas sim uma oportunidade para melhorar a confiabilidade do sistema. Algumas técnicas comuns incluem:
-
Blameless Postmortem (Sem buscar os culpados) Foca na falha do sistema, não nas pessoas. O objetivo é entender o que deu errado e como evitar o problema no futuro, sem punir ninguém. Isso incentiva uma cultura de aprendizado e transparência.
-
Linha do tempo do incidente Reconstituir os eventos na ordem em que ocorreram ajuda a identificar padrões e possíveis falhas no processo de resposta. Ferramentas como logs, dashboards e alertas são essenciais nessa análise.
-
Método dos 5 porquês Uma abordagem simples para identificar a causa raiz, perguntando repetidamente “por quê?” até chegar ao verdadeiro motivo do incidente.
-
Diagrama de Espinha de Peixe (Ishikawa) Ajuda a organizar visualmente as possíveis causas do incidente em categorias como Pessoas, Processos, Tecnologia e Ambiente.
-
Ações Corretivas e Preventivas Cada postmortem deve resultar em ações concretas para evitar que o problema se repita, como melhorar monitoramento, revisar processos ou ajustar infraestrutura.
-
Automatização e Melhorias Contínuas Sempre que possível, implementar automações para reduzir a chance de erro humano e garantir uma resposta mais rápida a incidentes futuros.
Por fim, um postmortem deve ser documentado e compartilhado internamente para que toda a equipe aprenda com o incidente. Com o tempo, esse processo fortalece a cultura de resiliência e confiabilidade da organização.
Conclusão
Os times de DevOps e SRE lidam com sistemas complexos, onde falhas podem causar grandes impactos. Ter métodos estruturados para resolver problemas e identificar suas causas raiz evita que incidentes se repitam, melhora a estabilidade e reduz o tempo de resposta. Técnicas como 5 Porquês (5Hs), Diagrama de Ishikawa e Blameless Postmortem ajudam a entender não apenas o que aconteceu, mas por que aconteceu e como prevenir no futuro. Sem uma abordagem sistemática, a equipe pode cair na armadilha de apenas apagar incêndios, sem realmente fortalecer a resiliência do sistema.
Além disso, métodos bem definidos garantem aprendizado contínuo e melhorias no processo, promovendo uma cultura de transparência e colaboração. Quando problemas são documentados e analisados de forma construtiva, a equipe pode otimizar monitoramento, automação e práticas de resposta a incidentes. Isso não só evita falhas recorrentes, mas fortalece o trabalho em equipe, ter boas práticas de resolução de problemas transforma incidentes em oportunidades de evolução para o time e para a empresa.
Abraços!
Vida longa e próspera a todos!!
Referências
- Equipes Brilhantes de Daniel Coyle
- Método Espinha de Peixe ou Diagrama de Ishikawa
- https://en.wikipedia.org/wiki/Debugging#Techniques
- https://pt.wikipedia.org/wiki/5W
- https://en.wikipedia.org/wiki/Five_Ws
- https://sre.google/sre-book/postmortem-culture/
- https://infraascode.com.br/tecnicas-de-troubleshooting/
- https://infraascode.com.br/k8s-troubleshooting/
- https://infraascode.com.br/postmortem-aprendendo-com-os-erros/
- https://infraascode.com.br/postmortem-aprendendo-com-os-erros-v2/
- https://infraascode.com.br/postmortem-aprendendo-com-os-erros-v3-final/
Entre em contato:
NewsLetter - https://engineeringmanager.com.br/Linkdin - linkedin.com/in/leonardoml/
Twitter: @infraascode_br
Te convido a ver os outros posts do blog Infra-as-Code garanto que tem coisas legais lá!!
|
|
